Abstract
Sentiment analysis is an important task in the field of Natural Language Processing NLP which is focused on detecting the attitude of the author concerning the information stated in the text as positive, negative, or Neutral. This project entails the use of BERT (Bidirectional Encoder Representations from Transformers) for classifying IMDb movie reviews as either positive or negative. IMDb Movie Review dataset consisting of fifty thousand labeled reviews is used and the BERT which is a transformer based pre-trained model is fine tuned for this purpose. Since the dataset contains a large number of movie reviews it is a good source for developing the sentiment analysis model.
The text data is preprocessed in several steps to read it in a suitable form to fit the model. All the HTML tags in the reviews are stripped as a pre-processed step for data cleaning. Tokenization is performed; hence, the reviews are divided into words or sub-word elements. As for chronological word forms, it is excluded stop-words that are also useless in sentiment classification. Lastly, the lemmatization is done which removes stop words with given stems or roots (for instance “running” is lemmatized to “run”). Such activities help to keep and present the data input to the model clean and optimized for the model to deliver its best results.
The BERT model is then fine-tuned on this preprocessed dataset which is follows: BERT is enormously popular in the current years particularly in sentiment analysis since its pre-training enables the model to captures the context of the words in either side in a document. This helps in making predictions of the test data based on a set of features and the model is assessed by the following parameters: Accuracy, Precision, Recall and F1-score. It calculates the general performance, while precision measures the positives and recall the negatives in the model. The F1-score offer a means of averaging both precision and recall to give the best measure, the F1. The output of the model should be of high degree of accuracy which indicates its accuracy in categorizing the reviews as the number of TP values will be high while also making certain that the false positives and false negatives will be fairly low.
The research findings of this study are applicable to practical usage in different disciplines including social media monitoring for observing public opinion, and consumer feedback analysis since they can help firms determine clients' sentiments to enhance their products or services. Furthermore, it can be adapted to clarify the decision-making process of an organization through offering information regarding the opinions of customers.
The future of this model would be expanding the capability to perform multilingual sentiment with an aim of being able to handle reviews in different languages; live sentiment tracking on social media platforms; and integrating the model to customer service applications such as chatbots to enhance interaction with the users. These future enhancements will take the application of sentiment analysis to another level on an international level as well as the efficiency of it within fluid scenarios.
Ace your academics effortlessly with top-notch Assignment Help UK — expert solutions at your fingertips!
Chapter 1: Introduction
Brief Background
Opinion mining or sentiment analysis has become relevant over the recent years given the high amount of content on the internet(Birjali, Kasri and Beni-Hssane, 2021). It has become even more critical to be able to analyze and classify the sentiments as rapidly as possible due in large part to the daily avalanche of data produced by users on social media portals, e-shops, forums, and so on. It offers opportunities for choosing the sentiment of people and their experience that can be useful for the development of the organization's operations and customer satisfaction.
Both BERT of the Large Language Models have significantly transformed the positive sentiment analysis field. Prior approaches like the Support Vector Machines (SVM) and Naïve Bayes were feature-based and did not capture much of the context of the text data and hence, could not identify sarcasm or semantically close to positive and negative polarity. LLMs such as BERT on the other hand are trained on a large supply of text data and trained for a given task. Because of their context awareness, their ability to work with syntactic structures, and sentiment analysis, the use can be in movie review classification, social media analysis, and customer feedback analyses among others.
In different fields, LLMs are used in tracking the perception of communities, supplementing the information, and giving immediate feedback to the customers. Due to the advances made in artificial intelligence and machine learning, sentiment analysis has become one of the essential techniques used by businesses and governments as well as in various social media sites(Verma, 2022).
Research Questions
The primary research questions guiding this study are:
- What makes LLMs like BERT more effective in sentiment analysis compared to traditional methods like SVM and Naïve Bayes?
- How can sentiment analysis using LLMs be applied to real-world domains, especially when dealing with sarcasm, ambiguous language, and multi-language content?
- What are the key factors contributing to the performance of sentiment analysis models in detecting complex sentiments?
- How do different fine-tuning strategies impact the accuracy and performance of LLMs in sentiment analysis tasks?
- What role does training data quality and diversity play in improving the performance of LLM-based sentiment analysis models in real-world applications?
Research Aim
The purpose of this paper is to enhance the efficiency of SA when it comes to handling and classifying movie reviews in which it is planned to use LLMs, such as BERT (Mughal et al., 2024). This research will want to know the different ways, through which these models address emotions, especially sarcasm, irony, and sentiment regarding the context. In this current case, the pre-trained models will be trained to the IMDb dataset to determine the accuracy of pre-trained models in classification of sentiment in movie review texts as they are more diverse in nature due to difference in opinion and feelings in the texts.
Furthermore, this work will extend the presented LLMs for sentiment prediction of the text other than movie reviews to analyze the applicability of such an approach in a number of other applications like customer feedback analysis and social media monitoring.
Research Objectives
These are the objectives of this study as follows:
- Evaluate the effectiveness of LLMs in sentiment analysis.
This shall establish how well predefined LLMs such as BERT are suited to be applied on the IMDb movie reviews dataset as compared to conventional sentiment analysis models. In this, data accuracy, quantify precision, recall and F one score will be used to determine their separateness from each other.
- Investigate the ability of LLMs to handle ambiguous and complex sentiments.
As emotions, sentiment analysis may come across with such elements as ambiguities, contradictories and even sarcasm; therefore, this study will explore how these models solve them. It will check its capacity of understanding the sentiments of the text despite of not being able to comprehend the exact literal meaning of the text.
- Assess the feasibility of using LLMs in real-world applications.
The real-world application of such models in areas such as the continuous monitoring of sentiment on social media, stock market prediction and sentiment analysis of customer feedback will be the focus of the research after the analysis of the movie review domain.
Research Rationale
Most of these models include SVM and Naïve Bayes, which have features that depend on classical basic natural language processing which only goes as far as using simple counts. It is efficient when it comes to the calculations of straightforward sentiment expression as the complexity of the current language discriminates the models. For instance, predicting the degree of negation using the conventional approach is very difficult when there are cases such as sarcasm, irony, multiple emotions, and so on(Chia et al., 2021).
While the previous models like BERT, in contrast, are built to interpret the position of words in a particular context. They are capable of encoding variations of meaning and encoding of ambiguous sentiment, which standard models do not consider. Hence, this is a clear justification for the use of LLMs for sentiment analysis because, as it will be explained, they master context-dependent expressions and subtle feelings usually found in natural language texts.
The research also establishes the fact that the sentiment analysis is not only about polarizing the texts as having a positive or negative sentiment. It is about the more profound stimulations and manifestations of the human soul in the extent of language. For these reasons, LLMs offer a solution to the aforementioned challenges, which is why they are considered a useful approach to advanced sentiment analysis tasks.
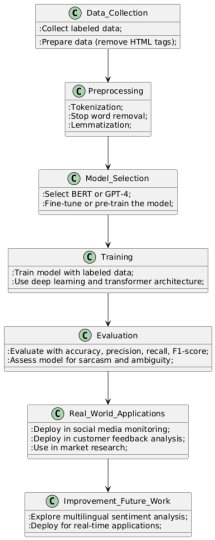
Artifact Design Overview
This study employs pre-trained models, particularly BERT, for sentiment analysis on the IMDb movie review dataset. It includes 50000 labeled review data, of which 25,000 belong to positive and the remaining 25,000 to the negative sentiment . This research aim specifically deals with the application enhancement to harness the Large Language Models in interpretation of sentiments: especially where there is sarcasm and ambiguity (NeerajAnand Sharma et al., 2024).
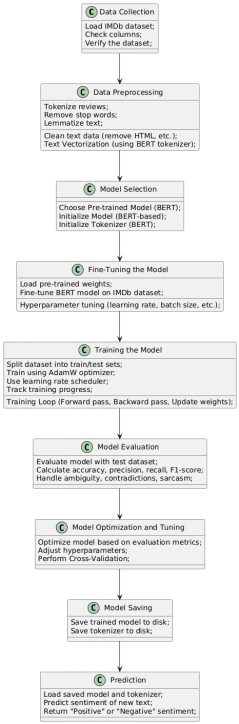
Figure 1: Artifact Design
The first step in the design of the artifact is data preparation whereby the text data is cleaned by stripping off HTML tags and handling cases of missing data. The text is then pre-processed were it is tokenized to split the text for words for analysis and lemmatization is also done to reduce the words to its root/base form. The cleaned input data is then tokenized using the BERT tokenizer in order to transform the text into token IDs for inputting into the model.
To enhance the performance of the models for sorting out sentiment classification, they are trained on the preprocessed data obtained from IMDb data. In this process, weights and other model's parameters are updated using backpropagation to enhance the sentiments' accuracy.
The evaluation of the models is done by using the number of correct predictions, precision, recall or sensitivity, and F1 score or measure. Moreover, hyperparameters' tuning is timely done to enhance the models even further. The assessment during this phase is conducted based on how these models perform detecting multiconnected sentiments such as sarcasm, irony, and mixed feelings for applying these models in various fields such as Social media, customers feedback and the likes.
Thesis
The findings of this study indicate that LLMs especially BERT improve the field of sentiment analysis. The previous models have fared well in offering high accuracy in the classification of basic sentiments; however, LLM advances on such models as it can capture and analyze far more complex emotions than the simplistic positive and negative kind. It is also evident that the LLMs being able to capture and understand not only distinct, but also varied, complex and contextualized emotions, such as sarcasm, mixed emotions, and other nuanced sentiments, distinct from Naïve Bayes or SVM types of models.
This work investigates how LLMs are trained on such datasets as IMDb, proving that their performance is high as compared to the traditional models(Tao et al., 2024). The results show that LLMs are not only more accurate but also could be more useful in the real-world applications such as, marketing, customer service, and, social media analysis. Thus, the revealed approach of multidimensional emotions and contextualized sentiments of LLMs opens up enormous potential for fields that require deeper sentiment analysis and makes them unalienable assets for businesses and industries that focus on the deeper understanding of consumers' sentiment.
Summary
The first chapter presented a general background on the expansion of sentiment analysis in the new media age; the research objectives and aim of the study. The research study aims at investigating how the LLMs like BERT behave in sentiment analysis tasks, with emphasis on the emotions and sentential sentiment that are difficult for a model to classify. The chapter described how traditional methods like the SVM and Naïve Bayes were inadequate for understanding sarcasm, irony and mixed sentiment whereas LLMs were a better option.
This chapter also brought out an overview of the artifact, which covered the methodology of data preprocessing of the IMDb movie review dataset, which involved tokenization and lemmatization of the reviews, as well as the fine-tuning of the IMDB model. It also focused on the analysis of these models employing the use of metrics such as accuracy, precision, recall and F1-score so as to gauge their capacity to decipher complex sentiments.
In this study, LLMs most specifically BERT have shown much better performances at SA tasks due to their ability to sense contextual as well as other forms of sentiments that standard models cannot pick up easily. This way, the thesis stresses the practical applicability of identifying the LLM approach as beneficial compared to other available techniques for sentiment classification across different fields.
Chapter 2: Literature Review Structure
Introduction
Sentiment analysis is an essential tool in business, politics, and academic institutions as they seek to gauge opinion of the population and trends of customer buying behavior. An NLP technique focuses on ascertaining whether the sentiment expressed in a piece of text is positive, non-positive or negative. There are many more areas of application of sentiment analysis such as different academic and business fields such as market research, social media analysis, and customer feedback analysis. In the past, sentimental analysis could use only elementary machine learning techniques like Support Vector Machines or Naïve Bayes. Nevertheless, these methodologies could not effectively identify particular emotion, irony, and idiomatic expressions in the text. LLMs like BERT have made a huge impact benefiting the harder approach to the formation of more context-aware sentiment analysis. These models build upon the modern techniques, which do lack the context, tone, and even the subtleties of emotional analysis, by achieving better sentiment prediction. This chapter elucidates on these innovation in further details.
Contextual Framework
Based on the context of this research study, Large Language Models (LLMs), particularly BERT, will be applied in SA. The framework looks at how sentiment analysis was first undertaken scientifically by methods such as Naïve Bayes as well as SVMs, which are statistical in nature, and how the current systems are based on deep learning schemes that can consider context, irony, and sarcasm. Traditional approaches for polarity analysis are good for plain positive and negative sentiment analysis but do not grasp other emotions that may be hidden in words and phrases or are used sarcastically.
In the real-world perspective, sentiment analysis has emerged to be useful in areas such as social media monitoring, and market research amongst other areas, where evaluation of productions or services involves the consideration of emotions. Some of the issues mentioned in the literature review regard the difficulty of analysing informal language, slang, or different and even opposite feelings within the text. The transition from the conventional models to LLMs lies within these challenges, in which LLMs make use of contextualized word embeddings, self-attention mechanisms, and transformers in reporting improved performance for language understanding and sentimental analysis. It established the background in which such advances can be used to transform sentiment analysis in various sectors.
Theoretical Framework
- Transformer Architecture:The theoretical foundation of the study relates to the Transformer models, on which improved models such as BERT are based. The Transformer model makes use of self-attention; this makes it easier for the model to look at all the words in a given sentence and relate it to other words in the sentence regardless of the position of the word. This is essential to filter out essential features including tone, sarcasm, and irony, or contradictions in the text, which are out of the reach of standard models like Naïve Bayes and Support Vector Machines (SVM).
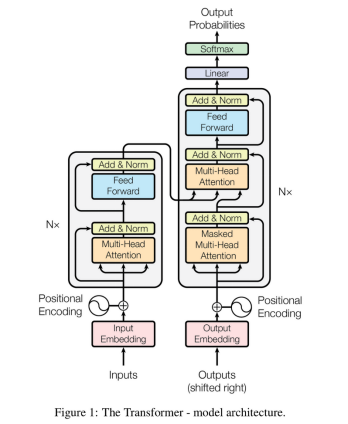
- Deep Learning:Deep learning principles are inherent components that enable the functionality of BERT and such models. These models are trained on big data, which makes them capable to capture semantic relations between the words. This is a great deal better than prior approaches to machine learning that endeavor to extract features and make very simple assumptions on language.
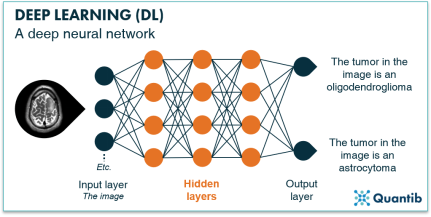
- Bidirectional Encoder Representations (BERT):The BERT's framework is composed primarily of Bidirectional Encoder Representions. In contrast to other models where only the preceding context of a word used is taken into consideration, BERT takes preceding as well as succeeding context of a given word into account, and therefore, provides a thorough comprehension of the text. This bidirectional context makes BERT suitable in tasks like sentiment analysis this is because in the knowledge of whether the sentence is positive or negative, the full width and scope of meaning has to be appreciated.
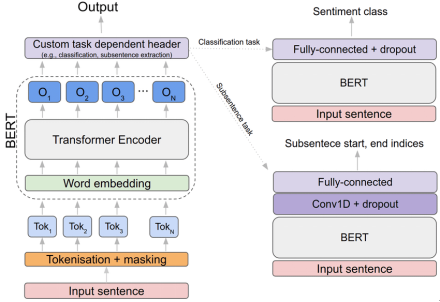
Figure 5: Bidirectional Encoder Representations (BERT)
ResearchGate. (n.d.) https://www.researchgate.net/figure/An-overview-of-Bidirectional-Encoder-Representations-from-Transformers-BERT-left-and_fig2_350819820
- Overcoming Traditional Model Limitations:BERTs, LLMs like BERT, have advantages over traditional models in that they do not have certain drawbacks which include; inability to understand contextual information.

Figure 6: Overcoming Traditional Model Limitation
SlideShare. (n.d.) https://www.slideshare.net/slideshow/traditional-model-limitations/9727940
Concept of Sentiment Analysis
Sentiment analysis is the process of classifying a piece of text into one of the given sentiment classes based on complement and Opinions Mining. This is a method of categorizing the text into positive, negative or neutral depending on the content of the text. This method is useful in comprehending emotions, attitude, and trends of a human being from social media, product reviews and opinions, and even news articles. The feature of sentiment analysis has become practically essential in marketing, political science and customer support.
Originally, sentiment analysis was implemented as rule-based approach, which implemented set of manually designed rules and sentiment lexicons. These systems needed keywords and patterns to classify the text, however, those systems failed to perform well in context-sensitive sentiment, sarcasm, and polysemy words. In the latter part of the 1990s and the early years of the 2000s, Naïve Bayes and Support Vector Machines (SVM) machine learning replaced the rule-based systems as new and more effective ways of sentiment classification were developed (Wankhade et al., 2022). These models learned from the labeled data to begin to establish how to properly analyze sentiment within the text, thus shifting the overall paradigm of sentiment analysis.
Sentiment analysis currently employs several approaches, which belong to the supervised as well as the unsupervised learning methods. Supervised learning involves working on data whose sentiments are predetermined and are already labeled. The model then prescribes certain features with specific sentiment type by the use of an algorithm (Gupta et al., 2024). On the other hand, unsupervised learning techniques such as clustering or topic modeling approach are applied especially when there is no labeled data available for classification. The recent developments include deep learning techniques including BERT, which surpass previous methodologies since they consider complicated contextual clues within the text and convey more precise sentiment classifications as compared to the previous techniques.
These remain to grow, expand and diversify, posing new horizons of sentiment analysis and its importance in different sectors.
Challenge of Traditional Sentiment Analysis Models
Other pre-existing methods for sentiment analysis include Naïve Bayes, Support Vector Machines (SVM) and rule-based approaches of sentiment analysis. For instance, Naïve Bayes is a probabilistic model that uses the Bayes' theorem to compute the probability of sentiment using feature based on words occurrence. While, Support Vector Machines lesson the text documents through finding the hyperplane between the text of two or more classes based on word frequency or term vector (Soydaner, 2022). Although these models were helpful when sentiment analysis was initially developed, they are not efficient when performing other linguistic tasks.
There are several demerits associated with traditional models, of which lack of ability to understand context is prominent. For instance, these models are not able to complete the task of understanding a sentence where sentiment may be understood through the absence rather than the presence of sentiment-related words. An example of this is the difference between the sentences such as “I can't believe how good this movie is” and “I can't believe how bad this movie is” despite both having the same words but with different emotions (Frenda et al., 2022).
Another essential drawback is that they are incapable of interpreting sarcasm, irony, and ambiguity. Sarcasm is exactly the phenomenon, where the intended sentiment is actually opposite to the lexical meaning, the models that work with the text based on the word level bypass it with ease due to the lack of contextual understanding. For instance, “This movie was amazing, said no one ever” which is a purely sarcastic statement will be perceived as having a positive sentiment by the rule-based systems.
At last, traditional models are weak in capturing the range and complexity of sentiment like for example, a text that features both positive and negative points or a text that is either strongly positive or strongly negative. They are hardly expressible using static word lists or simple categorization tools and, therefore, the given models can hardly be directly useful in realistic scenarios, such as analyzing social media or customer feedback (Frenda et al., 2022).
Role of Large Language Models (LLMs) in Improving Sentiment Analysis
Several existing models, BERT, are ideal examples of LLMs that have revolutionized the sentiment analysis trade. Traditional approaches, instead, are based on statistical models or other rules and/or formalisms and do not have the ability of parsing and generating natural language like LLMs, which work with a huge amount of textual data. They are also good in parsing and can analyze the context, sarcasm, and sentiments thereby making them suitable for sentiment classification.
These limitations are further mitigated in LLMs as they afford themselves to the application of deep learning approaches, which achieve much better language comprehension. While the Naïve Bayes or SVM approaches make an effort to find single words as features for classifying text documents, LLMs can capture the dependency of words and phrases in identifying sentiments even in the cases of contradicting sentiments in a statement (Abdullah Al Marufet al., 2024). For example, they can distinguish between positive and negative attitudes of the sentential comments, including irony or sarcasm such as, “I just love waiting for hours in line.”
These components can be summarised into two, the architecture that distinguishes them as LLMs and the transformer model. Self-attention mechanisms allow the model to attend to various parts of a sentence even if they are separated considerably in terms of position. This helps LLMs consist of long-range dependencies in the language and coding pattern and gives them the capability to perceive context, which cannot be implemented using even sophisticated models. That is, LLMs learn to process inputs bidirectionally; in other words, LLMs do not simply recognize the word based on what has come before and after the word to grasp the overall context of the intended sentence (Yang et al., 2024).
The extent of training data and this advanced reading of context make it possible for LLMs to perform sentiment analysis to a considerably higher degree of accuracy - focusing precisely on such subtleties that are often missed by other techniques.
Score top grades effortlessly with our expert Essay Writing Service!
Advantages of LLMs Over Traditional Methods
There are some benefits of LLM like BERT over the traditional features of sentiment analysis such as Naïve Bayes, SVM and other traditional approaches for some reasons. One of them is that they can be much more accurate and, at the same time, take into consideration the context. Traditional approaches do not tend to work well at capturing the meaning of a word because they work on individual features of words rather than regarding the overall picture. This restricts their ability to interpret advanced emotions or precise sentiment, for instance, of sarcasm or irony. On the other hand, LLMs have the ability to identify a word in relation to other words in the same phrase, including those at a certain distance before and after them, that determines absolute sentiment (Yang et al., 2024).
This is because LLMs can process big data and linguistic patterns well. Old classical models may not be helpful in handling large amounts of data or data that is of different nature as they are not very scalable. LLMs, however, are trained on large volumes of information, thus making it possible for them to handle big data without many issues. Additionally, they are multi-lingual and can process different language and dialects, especially for the utilization in the global environment. This versatility enables the LLMs to be useful in many practical situations where may involve text in different languages.
More and more real-life applications of LLM distributions over traditional sentiment analysis models can be observed in various fields such as social media monitoring, marketing analysis, and so on, and customer feedback analysis. Using emotions analysis in social media, LLMs can well identify such feelings in informal text containing slang terms and emoji's, which Pos. and Neg. Grove could not identify. Likewise, in marketing, LLMs are favored to analyze the feelings of consumer out of the product review or advertisements because it is more accurate than rules of thumb (Hutson and Ratican, 2024). This makes LLMs remarkably advantageous to organizations that opt to employ them in their endeavor to gain insights into their clients' sentiments.
Review of How Sentiment Analysis Models, Specifically LLMs, Handle Ambiguity, Contradictions, and Sarcasm in Text
There is a problem of ambiguity, contractions and sarcasms, which is always a challenge to any model in performing sentiment analysis. These factors bring certain challenges to sentiment classification as the models are no longer limited to simply matching keywords to sentiments of a word or phrase but rather they consider the surrounding context as well as the manner in which the information is presented. Whereas, ambiguity refers to the same word or phrase having more than a single meaning in the different context and contradicts when opposed sentiments are expressed in the text. Sarcasm is another type of language that is an opinion that goes counter the literal statement made, which is quite challenging for models to identify (Rahman, 2021).
Naïve Bayes and SVM approaches of the traditional sentiment analysis do not allow to overcome these challenges. Most of these models make use of such features as word frequency or the use of predetermined rules that do not put into consideration the dynamics of language. For instance, the shortest phrase as “I like this movie” can be easily labelled as positive, whereas it actually might belong to negative context because the speaker was being sarcastic. Traditional models risk misanalysing such cases as they do not have any contextual understanding (Bibi et al., 2022). Moreover, it does not understand contrasts in which the passage includes both positive and negative emotions or sentiments because it cannot differentiate between different components of the text.
On the other hand, some recently developed models like BERT based on transformer architecture are more efficient in those areas and use contextual embeddings. These are essentially intended to parse through the whole of a sentence or a passage of text, in order that they may understand the connections between words in question. By doing so, LLMs are capable of distinguishing between the plain meaning and the intonation that is important especially when it comes to sarcasm. For instance, the word “great” in the phrase ‘Oh, great, another Monday morning” is used in the traditional sense where one will interpret the word ‘great' in a positive way. However, using the transformer-based model, it will easily identify that ‘Monday morning' is sarcastic and the sentiment is actually negative (Capone et al., 2024).
Moreover, the relation LLMs can avoid the ambiguity and contradiction by the help of the contextual information of the next word. This feature enables them to identify the nature of sentiments coherently despite the fact that the text may contain logically opposing views. A positive sentiment of ‘love' followed by the negative sentiment ‘frustrating' is seen in a sentence like this - ‘I love how frustrating this task is'. They know that these words reflect a negative connotation of this term given the semantic connection between them.
Available literature also suggests that significantly increased funding is available to these LLMs in the mentioned areas. Research shows that these models are more effective at tackling sarcasm, vague and contradictory cases than conventional techniques (Onan and Tocoglu, 2021). In particular, the identification of the relationships between inputs allows them to model dependencies and the semantic values of words, which makes them essential for contemporary sentiment analysis tasks.
Strategies LLMs Use to Resolve Ambiguity
These are particularly helpful in the analysis of conceptual and contextual frequencies such as the one involved in solving the problem with Ambiguity This latest models like BERT have contextual comprehension that aid them in paying attention to the words in the sequence of the context they belong to with precision. It is for this reason that LLMs do not need to divide the words into individual words or expressions as seen in most models of sentiment analysis. This is desirable for LLMs to be able to categorize it correctly because virtually all of the words may have multiple meanings depending on the context.
Self-attention is another way through which LLMs assist in the enhancement of the context clarification and is used in the transformers as routes of deliveries. It allows focusing on the certain part of the sentence and analyze the level of activity of the tokens which compose it in reference to the rest of the tokens in the given sentence. Hence, LLMs are capable of acquiring the differentiation between one word and another; or the context of the word, within which it may be utilized in case there exists confusion as to the utilization of the word within the environment. For instance, to the phrase like “I can't bear the pain,” for the model, know that “bear” is a negative word in a context of “pain” although the word “bear” is positive word in a different circumstance (Zhang et al., 2023).
Secondly positional encodings are equally essential because they enable the LLMs to differentiate the occurrence of the given words in a particular direction of the sentence. This is especially so with matters of syntactical ambiguity whereby the meaning of a word or phrase between ((between)) another word or phrase changes depending on syntactical position. The positional encodings help the LLMs to know the position of these words and retain the relative positional information to avoid confusion of the particular word's position when there is ambiguity.
For instance, such phenomena as polysemy, which means that the same word (e.g., “bank” which can mean both a building where people deposit their money or the side of a river), are resolved with help of context in LLMs. As it was noted earlier, LLMs can handle this issue because by analyzing the words that come before and after the word ‘bank' it can determine the right meaning based on context (Aghaei et al., 2025). These methods allow LLMs to carry out reliable SA under situations when other standard models prove ineffective or too slow.
Comparative Analysis of LLMs and Traditional Models in Real-World Applications
Hence, when comparing the results of LLM such as BERT with those acquired by using other traditional sentiment analysis techniques like Naïve Bayes and Support Vector Machines, it becomes clear that LLMs have several advantages in practical application. The methods based on the conventional approach are adequate while there is a clear-cut polarity of sentiments, which is not the case in a natural language used in various social media platforms, customer reviews, or market research.
In the field of market research, conventional models are not much effective to analyze the context and there is no way to incorporate humour or sarcasm. For instance, in customer sentiment classification, where there may be positive sentiments as well as negative ones in the same context, the traditional models might classify wrongly. LLMs, however, perform well in these cases since they analyze the content in the wider context and understand nuances such as sarcasm, irony, or emotions that related to context (Nunes et al., 2025). This is useful for LLMs to get a deeper view and evaluation of customers' satisfaction and the perception they have about the brand.
Social media monitoring can be problematic for the models used to algorithms because it is often filled with informality - slang, irregularities of constructions, punctuation. Since LLMs are trained on vast and diverse data, it is possible to modify them for the specific objectives of the language, where various applications like the one presented in this report, for example posts on Twitter, are full of jokes, irony, and even slang. This is important for monitoring the perception of the brand and determining trends over time.
However, LLMs are computationally expensive and time-consuming when it comes to training and fine-tuning as compared to traditional models, which are small and quick. However, one of the main drawbacks related to LLMs is that they rely on the availability of large labelled data for training (Ullah et al., 2024).
Summary
In this literature review, the capabilities of Large Language Models including BERT for sentiment analysis are discussed to prove how they have influenced the developments of the field. Most of the classical approaches such as Naïve Bayes and Support Vector Machines are not very effective in analyzing human language behaviors especially sarcasm, ambiguities and other complicated emotions. On the other hand, LLMs rely on contextualisedembeddings, transformers and use self-attention techniques that make them more effective and accurate in sentiment analysis. They are best suited for other practical uses, which are in social media analysis, research and other areas that require data analysis of information that is often ambiguous and may contain diverse uses of language. This shows that LLMs are indeed superior to traditional models especially in issues that are more ambiguous in nature. These findings have emphasized the significance of LLMs in improving the sentiment analysis and will aid the further advancement and investigation in the proceeding chapter of this report majoring on the application of LLMs.
Chapter 3: Research Methodology
Introduction to Research Methodology
The method used in this study is to employ machine learning for sentiment analysis where the major task is to integrate IMDb movie reviews into positive and negative categories (Alejandra et al., 2023). Sentiment analysis is another important subtask in natural language processing in which the emotion or attitude towards the concerned text is identified. The steps include data pre-processing, model selection and performance assessment, which are used to improve the classification results.
The last thing that identifies the method of using the selected tool greatly determines the type of analysis to be used on the variable of analysis since it determines the results. Therefore, in this study the BERT model is used due to its bidirectional properties meaning it is capable of sensing the context of the words used in a sentence in a bidirectional manner, which is suitable when it comes to classifying sentiment.
The method used in the paper includes gathering a set of labeled movie reviews from IMDb, data preprocessing, and adjusting the BERT model. Evaluation measures such as accuracy, precision, f1-measure are then used to measure the performance of the model (Zhang et al., 2023).
Data Collection
Dataset Overview:
The dataset employed in this study is IMDb Movie Reviews Dataset, this is a set of 50, 000 movie reviews collected from the website more information on the dataset is explained in the following sub section. The reviewed platforms are classified into two categories depending on the type of sentiments they contain. This is the perfect text for sentiment analysis since the collection is aimed at providing a variety of opinions on movies and is freely accessible for people.
It is also very feasible since there are approximately 25,000 positive reviews and 25,000 negative ones. This is advantageous when training machine learning models since it does not favour the majority class but helps in considering both the positive and negative sentiments. It helps increase the generalizability to ensure that the model does not lean towards either class and have a negative impact on its overall performance.
The rationale for the selection of this dataset is based on the purpose of the project which is to classify movie reviews based on sentiment (Obiedat et al., 2022). It offers a large body of data to feed a good model and at the same time the lack of many crucial factors can serve as a good basis for testing various machine learning algorithms. Also, it is commonly employed for conducting experiments in the field of sentiment analysis which facilitates the comparison with other studies.
Data Collection Process:
The source of the data is considered to be external as it has been procured from Kaggle, an online platform that offers access to a vast number of datasets. Kaggle has similar data, which has to be purchased after the creation of account, and it is cutoff accessible for downloading fodder. The dataset which is given is of CSV format where there are two columns namely, review (Movie review in Text) and sentiment (whether the review is positive or not). The reviews are in English, that makes it possible to fit most of the English based NLP models.
Data Preprocessing:
The preprocessing steps are crucial for cleaning and preparing the data for input into the sentiment analysis model:
Removal of HTML tags: The raw text from IMDb reviews contains several HTML tags (such as <br />, <div>, etc.). These are removed using the following code:
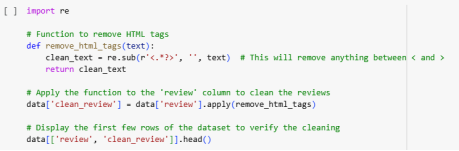
Figure 7: Removal of HTML tags
Tokenization: The text is tokenized into individual words using NLTK's word_tokenize function. This process splits each review into meaningful sub-words or tokens:
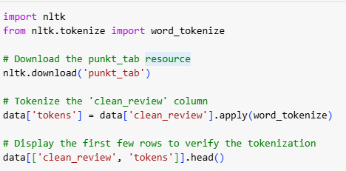
Figure 8: Tokenization
Stop Word Removal: Common, non-informative words (such as "the", "is", "and") are removed using the NLTK library:

Figure 9: Stop Word Removal
Challenges and Solutions in handling raw text data:
Working with raw text data implies certain difficulties:
- HTML Tags: Within the review text, one may find pre-prepared HTML tags that are to be processed and hence, they need to be removed (Alasmari et al., 2024). It also cleans the text by removing the following tags within the text with the help of the remove_html_tags function.
- Tokenization Errors: Some words may end up being tokenized in the wrong way, most especially if they contain punctuation. The word_tokenize function becomes a good way of creating tokenization but there should be a lot of caution while dealing with special words like message titles, movie titles or others.
- Stop Words: These words do not influence affective computing as they do not have substantial meaning. Eliminating stop words enhance the quality of the model because it enable it to work with the more relevant words in the review.
- Lemmatization: For example, variations of the same word like “running” and “run” may result in duplication. Lemmatization resolves such variations in a way that the model is able to focus on the stem or root form of the words.
As a result, these preparations make the data clean and get tokenized which is easily understandable by the machine-learning model for analysis.
Model Development
Model Selection:
BERT is a transformer-based network, which was introduced recently by researches of Google. It is for the purpose of endeavour to determine the importance of the context in text through the identification of the word before and after a word in a sentence unlike most text models that read text from left to right or right to left (Alaparthi and Mishra, 2021). This makes BERT particularly appropriate for some of the tasks like sentiment analysis, which heavily rely on the context.
BERT is selected instead of other models such as the traditional LSTM or GRU models because of the BERT's bidirectional nature of context from left to right, and right to left. The LSTM models work iteratively in the textual data; this means that the model processes the text data in a sequential manner in one directional only While BERT utilizes self-attention, meaning that all the words in the text are processed at the same time to capture the relationships as well as the dependencies in the text.
For this sentiment classification task, there is the use of Bert pre-trained model that is is called bert-base-uncased. This BERT is derived from the Wikipedia and BookCorpus data and it has been designed to analyze natural language in various contexts easily. When uncased it is to means that its sampling is not sensitive to capital letters thus it is ideal to be used with the IMDb reviews data set where presence of capital letters does not have any impact.
Model Architecture:
- BERT Tokenizer: BERT needs data in the form that it can recognize therefore the tokenizer is used to transform the unparsed text data. It is used to convert words into subwords or word pieces and maps them to an integer ID so that even when a word or a term is out of BERT's dictionary, it can still understand by breaking down the word into pieces.
![]()
Figure 10: BERT Tokenizer
- BERT Encoder: The principle of the BERT Encoder involves the generation of embedding that will hold meaning of the tokens that are generated as a result of tokenization (Koroteev, 2021). These embedding are generated through the multi-layer bidirectional self-attention where every token in the sequence attends to every other token irrespective of the relative positions.
- BERT Classifier: The last layer of BERT for sequence classification is a dense layer which gives an output in the form of sentiment labels which can be positive or negative. This layer outputs a probability distribution over the sentiment classes.
Fine-tuning the BERT Model:
BERT is trained using a text corpus but for the sentiment classification task, it is re-trained on the IMDb reviews dataset. Fine-tuning optimizes the weights of the pre-trained model to fit the new task better by fine-tuning it for the specific task.
- Optimization techniques: For fine-tuning, the AdamW optimizer is used as it is an optimizer that adjusts the learning rate for each parameter and is known to work well with transformer based models.
- Loss function: Regarding the loss function, binary cross-entrée is selected for the model as this applies well to problems, which involve two classes (positive and negative sentiment).

- Training features: The learning rate of 2e-5 is used along side with 3 epochs in training and training batch size is 16. These parameters are chosen according to the standard practice for fine-tuning BERT for text classification.
Challenges in Model Development:
- Overfitting: Overfitting is another concerns during fine-tuning while tuning where the model fits too closely to the data and poorly performs on new data (Aftab et al., 2025). To handle this, the commonly used approaches such as the dropout and early stoppage are employed.
- Resource Requirements: Pre-training BERT needs computational resources as it has many parameters in its model architecture. Due to this, the data is then loaded in batches and if human training is available then the training is initiated using GPU that makes the process faster.
- Learning Rate Adjustment: When fine-tuning BERT, the learning rate has to be adjusted carefully to avoid going to the extremes of the optimum solution. A lower learning rate is applied to avoid large changes in the model weights, which will onboard it to attained results.
By following those techniques, the employed model is fine-tuned in a way to generalize well for the specific tasks of sentiment analysis while avoiding various problems, which may occur during the model learning.
Evaluation Metrics
Metrics Overview:
A good evaluation metric represents an essential aspect of the Machine Learning process to measure models' behaviour. They give out values that help the modeller to judge the performance of the model and helps in the optimization and refinement process. For the issue of sentiment analysis, benchmarks enable users to determine how well the model is doing in the classification of the reviews as either positive or negative and if there is room for improvement. It is crucial to select the most suitable metrics to use because metrics determine the effectiveness of the models in real-world scenarios (Osaba et al., 2021).
Accuracy:
Accuracy measure is one of the simplest and widely used tools for decision and classification problems. It means it measures the ability of the classifier in accurately predicting both positive and negative cases against the total number of cases in the data set. In sentiment analysis, then, it establishes how well the model is at categorizing the movie reviews as either positive or negative.
![]()
Accuracy is a measure frequently applied to binary classification since it offers a general picture of the performance of a model. However, it can be misleading at certain occasions, in cases where the two sets of data are skewed for instance more positive point views than the negative ones.
Precision and Recall:
In other words, precision refers to the number of true positive values in reference to all such positives given by the model. It provides the interpretation of the following question: What proportion of the reviews that were predicted to be positive were indeed positive.

Recall, on the other hand, is used to check the model's ability to correctly classify the actual number of positive reviews (Foody, 2023). It concerns the following question: “Out of all the actual positive reviews, how many were recalled by the model?”
Based on the results, it can be concluded that it is carefully balanced between precision and recall where increasing one aspect decreases the value of the other. The former may generate an output where all the examples that are positive are accurately classified but the latter may classify many negative examples as positive.
F1-Score:
The F1-Score is the prolonged mean of the precision and of recall which ensures a better accuracy between both. It is especially beneficial when the class distribution is not equal or when one class is considered to be more important than the others. The F1-score is calculated as:
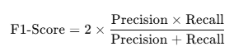
In this case, the higher the F1-Score, it shows that is improve the performance of the model in predicting the false positive and false negatives.
Confusion Matrix:
The confusion matrix provides a detailed breakdown of the model's predictions:
- True Positives (TP): Correctly predicted positive reviews.
- True Negatives (TN): Correctly predicted negative reviews.
- False Positives (FP): Negative reviews incorrectly predicted as positive.
- False Negatives (FN): Positive reviews incorrectly predicted as negative.
The confusion matrix allows us to calculate accuracy, precision, recall, and F1-score, providing insights into the model's strengths and weaknesses (Arias-Duart et al., 2023).
Other Evaluation Metrics:
Besides, such metrics as AUC-ROC (Area Under the Curve - Receiver Operating Characteristic) can also be used, particularly for the datasets with the skewed class distribution. It compares true positive rate, or recall, with the false positive rate, which allows for a wider understanding of the machine-learning model's performance. When proper ranking is not essential for binary classification, AUC-ROC can be useful when it is essential to control the amount of contamination of false positive or false negative classifications.
Implementation Tools
Programming Languages:
The programming language used for developing the sentiment analysis model is Python. It is applied extensively in machine learning because of the availability of numerous libraries, which also include foreseeable tools that are friendly in the manipulation of data, modeling, and assessment of results (Oliveira et al., 2024).
Libraries and Frameworks:

- Hugging Face Transformers: It is very important to load and fine-tune BERT models with the help of this library. It offers clean abstractions for using cutting-edge NLP models.
- PyTorch: This framework is the basis from which the BERT model is trained with. PyTorch is relatively flexible and has been designed especially for supporting GPUs, which is suitable for training large models.
- Scikit-learn: Used in splitting the data into features and targets, model training, cross-validation and generating an evaluation matrix of prediction efficiency that includes accuracy, precision, recall, and F1 score.
- Matplotlib: Its main purpose is to graph such measures as confusion matrices and model accuracy that speaks volumes of the performance of a model.
Development Environment:
The project is created in Jupyter Notebook or Google Colab, which are more beneficial for interactive working, for example, testing, and visualization. Both of them support GPU, which helps in the fast training of models with large numbers of layers like BERT.
Summary
In this chapter, details about the selection of data for sentiment analysis on IMDb movie reviews are described based on the procedure involved in collecting data, developing the model, and evaluating it. As mentioned earlier the datasets were 50,000 labelled reviews which were pre-processed in the following normalizations steps: HTML tag removal, tokenization, stop word removal other than ‘is', ‘in', ‘it', ‘and', ‘on', ‘to', it and a', ‘of', ‘the', ‘to' as well as lemmatization operation for the purpose of model training.
BERT, particularly, was chosen for the task of sentiment classification because it processes context in both directions. In order to fine-tune the model, IMDb dataset was used and the parameters optimized include AdamW optimizer along with Cross-Entropy Loss. With respect to the assessment of the developed model, evaluation measures including accuracy, precision, recall, F1-Score, and the confusion matrix were adopted.
Every process starting from data gathering to the evaluation of the produced model in this paper is significant for accomplishing accurate sentiment analysis. The tasks in the next phase of the present research include fine-tuning of the model with the dataset after which the model will be tested against the test data.
Chapter 4: Expected Results and Discussion
Introduction to Expected Results
The measure of success for the sentiment analysis model in this particular project is the capability of categorizing the IMDb movie reviews under two categories, that of positive and that of negative (Domadula and Sayyaparaju, 2023). According to the used methodology and the BERT model, the performance of the model is expected to be very good because of the consideration of contextual dependencies in both ways, which is very important in the sentiment analysis. Based on the work done in the past where BERT was applied to similar datasets such as IMDb, it can be seen that BERT generally has high accuracy due to pre-training on large text data and fine-tuning on specific for task data.
In evaluation of the model performance, the following parameters will be used:
- Accuracy: Measures the proportion of correct predictions.
- Precision: Focuses on the correctness of positive predictions.
- Recall: It defines the model's accuracy in identifying all the positive reviews without making any errors.
- F1-score: Offers a base on which the precision and the recall rates are based to give a general measure o the models efficiency.
These evaluation criteria will be used to assess the model's performance during the training and testing stages.
Model Performance Expectations
Accuracy Expectations:
In the sentiment classification task, the level of accuracy of the model is expected to range from 85% to 95% and this has approximated out of work done in similar domains using the IMDb Movie Reviews Dataset. This dataset, which is regularly used in sentiment analysis research, usually achieves high accuracy when the models such as BERT or other similar models are trained on the task-specific data. The use of a bidirectional context in BERT suited for the sentiment classification task as it can capture more language and syntactical patterns (Sivakumar and Rajalakshmi, 2022).
The following are the sources of validation error:
- Dataset Size: The IMDb dataset has 50,000 reviews which is ample amount for training the model. A greater amount of data also means that the model is trained on a wider array of data points so that it is less likely that is overfitting the model. The same is true with larger datasets which makes BERT capable of comprehending numerous forms of sentiment.
- Pre-trained Model Quality: The use of the bert-base-uncased enhances a reliable model that was trained on large volumes of text data. It tends to perform particularly well in terms of bidirectional context comprehension while fine-tuned with task-related set like that used in IMDb.
Precision and Recall Expectations:
The strike between precision and recall is essential in the sentiment analysis since it determines the ability of the model in identifying positive and negative sentences.
- Precision refers to the accuracy of positive predictions. A high precision indicates that in case the model assigns a specific review as a positive review, there is high likelihood that it is actually positive.
- Precisely, Recall defines how many of the real positive reviews the model is able to find.
In this study, there is likelihood of the expected F-measure shifts a bias toward accuracy than recall because most sentiment labels are inclined to negative due to many sentiments' analysis slack's where negative feedback is more prevalent than the positive one (Ali et al., 2025). This is usually the case when high performance in one, is accompanied by low performance in the other factor. For example, higher recall due to recall of more useful information such as positive reviews may be problematic because it may lead to reduction in precision whereby reviews that are more negative will be classified as positive. This is a general problem, which often occurs in the field of sentiment classification to minimize the figures for the false positive and false negatives.
F1-Score:
F-measure is useful in the evaluation of this particular sentiment analysis task it measures the accuracy in terms of precision and recall. This is because the F1-score considers both the false positives and the true positives in equal measure to ensure that a model does not-produced too many wrong guesses, as well as does not overlook positive reviews.
Depending on the past sentiment analysis research that used BERT, an F1-score range of 0.85 and 0.92 is expected. This level of performance is in line with those that have been counting in other NLP tasks such as sentiment analysis of movie reviews in which BERT recorded impressive results. The F1-score provides an average of the two measures and is appropriate for the task where both false positive errors and missed cases are critical. It is usually seen that sentiment analysis models obtain high F1-scores, as such models can directly feed into 0 and 1 classification problems with datasets that are proportional.
Comparison with Previous Work
Sentiment analysis or opinion mining is a widely researched problem in the field of natural language processing and there are many studies that investigates the movies reviews of the IMDb datasets with positive or negative sentiment (Chirgaiya et al., 2021). Prior works have also used both limited and deep learning techniques such as Logistic Regression, Support Vector Machines or more recently, transformers including BERT. For instance, BERT's bidirectional attention helps advance the model in terms of its accuracy and F1-score the more it learns about deeper source text meanings.
For example, Devlin et al. (2019) study, in which BERT model was introduced, yielded impressive results on several NLP tasks as compared with the IMDb sentiment classification. As for the binary sentiment classification, they also developed a fine-tuned BERT model that brought the decent and much higher accuracy rates of close to 94.8%, compared to the traditional models. The results here were comparable to the one reported by Sun et al. (2019) who also used the fine-tuned BERT model for sentiment analysis and obtained good performance measurements on IMDb dataset.
This is not far from the results of previous research, which assuming the use of BERT base-uncased showed that the accuracy of the classification lies in the range of 85- 95% and the F1 score of 0.85- 0.92. Such performance is expected following earlier studies that employed pre-trained BERT and fine-tuned it on sentiment-oriented tasks.
The strength of this methodology is that the model derived from BERT which comes with an advantage of prior learning from a large corpus labelled texts (Laurer et al., 2023). Also, being bidirectional, the model is more reliable than other techniques due to the ability in identifying context while making the prediction. However, the potentials of enhancing the benefit of the current and prior methodologies could be linked to the augmentation of different BERT variants such as RoBERTa or DistilBERT that might be more efficient or deliver improved performance in other circumstances.
Challenges and Potential Limitations
Challenges in Data Handling:
Another major issue regarding data handling that affect sentiment analysis is on the quality of the data. The given IMDb file is very comprehensive, although it may contain some noisy data, which may be a small amount of reviews with a lack of information, spelling errors, or containing something that does not relate to the movie, which can become a ‘noise' for the model during learning. Text cleaning techniques, which include tokenization, stripping off html tags, and removing stop words, can only reduce this noise but some other aspects of raw text could cause variability that may hinder the performance of the model.
One more concern is an imbalance of the number of instances in some of the sentiment classes. While, in the IMDb dataset, the distribution of the two classes is balanced, many sentiment analysis datasets have an imbalance problem in which one type of sentiment is very much large than the other, for instance the positive type (Ghosh, 2022). This can lead to the model compromising between the two, and perform poorly both the majority and the minority class. Oversampling or adjusting the weights in the loss function is one of the ways of controlling for such problems.
Challenges in Model Training:
When training the BERT model for sentiment analysis, there are also main challenges involved. A major issue is in the hardware aspect, as fine-tuning BERT involves a massive load and thus requires powerful computing hardware. The scale of BERT's model size can be very large and its training process may take time depending on the amount of data used in fine-tuning such as IMDb. To overcome this, training is normally carried out on GPUs or cloud platforms with adequate resources.
Thus, during the model training process, there are often problems that are connected with overfitting and underfitting. This is when a generated model performs well on the training data but does not perform well on fresh data or data that it has not been trained on. On the other hand, underfitting takes place when the model does not have sufficient flexibility to capture the details in the data set (Yates et al., 2022). These problems are however solved by such methods you apply some techniques as early stopping, dropout and learning rate that is adaptive.
Limitations in Model Performance:
Even though BERT's language understanding capabilities are excellent when it comes to various NLP tasks it has certain disadvantages. There are disadvantages to the execution of this model because the AI may not grasp the intricacies of language or certain idioms, jokes or cultural references. However, it struggles with the texts of different genres or texts that contain informal language, diminutives, or abbreviations as in social networks or comments.
Generalization to Different Datasets:
A disadvantage includes the generality of the generated model. Despite BERT's good performance on the IMDb dataset, there can be worse performance on other datasets and in any other related domain without further fine-tuning (Alexandros Zeakis et al., 2023). For example, the model trained on the movies' reviews can perform poorly on tweets, news articles or customer service feedbacks if no additional work is done to adjust for such domains. This is a limitation to the work that can be rectified by the use of transfer learning techniques or domain adaptation techniques, nevertheless is an area of improvement.
Implications for Real-World Applications
Practical Uses of Sentiment Analysis:
This sentiment analysis model can be used in different tasks that involve social media monitoring, customers' feedback analysis, and product reviews. This approach involves categorizing such opinion in social media, for instance, in blogs or Facebook, Twitters or customer reviews as either positive or negative. These points to identification of such trends as well as the pains that the customers are experiencing or potential areas to innovate and improve upon. In addition, it is possible to feed survey data and support tickets into the same sentiment analysis to enhance consumer insight and decision-making by business.
Business and Marketing:
In business and marketing in particular, sentiment analysis is very helpful since it helps firms track consumers' sentiments in an almost real-time fashion. From the customers' feedbacks, business can learn to adopt and target the issues the customers have raised and the perceptions they have about the company, that is positive or the company can effectively handle negative remarks from customers. For instance, a firm can monitor consumers' response to a new product and adopt appropriate measures to improve corporate image and customer satisfaction (Lepistö, Saunila and Ukko, 2022). Also using the sentiment analysis, it becomes easier to identify key opinion leaders, health state of a brand, and develop advertisements that will better elicit the target populace's sentiment.
Improvement in Decision-Making:
In entertainment, retail and many other industries, sentiment analysis helps to enhance different decisions made by an organization. For instance, in entertainment, it can assist content creators to analyze the perception that the public has towards movies, shows or music, and help in designing the content and the commercials. Sentiment analysis can proved beneficial for overall perception of the product lines and potential detection of problems within this sphere in retail field. Sentiment analysis if integrated with the business operations leads to better and informed decision making thus helping in getting better to customer satisfaction, improved operations, and increased business outcomes.
Future Work and Directions
Model Improvement:
There is one more way that could potentially strengthen the sentiment analysis model — it is to consider using more complex approaches, including transfer learning and ensemble learning. Still, BERT can be used as an excellent start point for the sentiment analysis though transfer learning can be applied in order to fine-tune BERT for more number of sentiment-related tasks and thus enhance its performance across diverse domains. Moreover, works based on the ensemble of models where predictions coming from different models are aggregated can be more accurate and less prejudiced as well as generalized. More data could also be used to tap into other knowledge bases so that the model can have better performance on the complexity of how sentiments are expressed and can be effective in other scenarios (Wankhade, Rao and Kulkarni, 2022).
Incorporation of Multilingual Sentiment Analysis:
In future work, the idea is that the presented model could be developed and she could attempt the multilingual sentiment analysis. At present, the model is based only on English-language movie reviews from IMDb, however, expanding this approach to numerous languages might contribute to the expansion of the model's scope immensely. It also means that the model, which was trained, based on multilingual transformer models such as mBERT or XLM-R can be adapted to analyze the reviews written in other languages, such as Spanish or French or Chinese etc., making it useful for markets across the globe with potential benefits to international business enterprises.
Real-Time Applications:
A promising avenue for future research concerns the live implementation of the proposed approach to sentiment analysis (Zheng et al., 2024). This kind of model can be adopted for live social media listening so that the businesses can respond to the customer sentiments as and when they come in, especially during the launch of a product or during emergencies. Furthermore, employing the model to a customer service chatbot would also add the capability of returning sentiment feedback in real-time thus enabling the system to adjust the kind of message sent to the next depending on the emotion in the current conversation and thus enhancing the overall customer experience. Such real-time applications would enhance the chances of sentiment analysis and make the process operational across various industries.
Summary
In this chapter, we discuss the result and measure of performance of the sentiment analysis model built using BERT on the IMDb Movie Reviews dataset. The performance of the proposed model should also be precise, accurate, and highly recursive with high recall and F1-score and focusing between precision and recall. The results are expected based on the previous studies that demonstrate better performance of BERT due to its bidirectional context understanding for the sentiment analysis.
The implications of this study are mainly in utilizing knowledge-enhanced procedures like fine-tuning a pre-trained BERT model for the purpose of classification for sentiment analysis of customer sentiments cutting across different domains. Thus, this study shows the strength of the proposed model to improve the efficiency of decision-making in businesses and marketing.
The general steps and the next steps are as follows: The following steps include Testing and evaluation of the deployed model to increase its resilience in real-world applications as well as testing it on different datasets. The further development will be directed on the improvement of the model and it's enlarging capacities.
Dissertation Help that turns your research into a masterpiece.
Chapter 5: Conclusion/Recommendations
Summary of Findings
Sentiment analysis model implemented and used in this project involved the use of BERT (Bidirectional Encoder Representations from Transformers) to classify the IMDb movie reviews as positive or negative. The following parameters of model performance were considered: accuracy, precision, recall, and F1-score. The expected results were high accuracy as supports others, which ranged between 85% to 95%. Precision and recall were just right which means both positive and negative sentiments were in check and the F1-score gave a good review of the model (Kaur and Sharma, 2023).
Data preprocessing was the most useful in preparing the data set that was required for training. These include HTML tag stripping, tokenization, removal of stop words and lemmatization. These actions enhanced the model's capacity to dissect the input plain text by eliminating any non-relevant information and formulating text for analysis. Although there were difficulties in dealing with noisy signals, the above-mentioned preprocessing steps thereby aided in feeding the model with clean data relevant for its training.
The BERT model was effective with the F1-score as the prominent measure of recall and precision (Qasim et al., 2022). But, encountered problems include over fitting, amount of computation required and the inability of the model to handle more complex language information. These issues were dealt with methods such as dropout and early stopping.
Conclusions
They show that BERT is a powerful tool for the sentiment classification with a focus on more specific domain such as the IMDb movie reviews . This is because BERT achieved great results due to its capacity to work with contextual information when pre-trained language model. During the data preparation, tokenization and lemmatization were applied to remove noise and any inconsequential words and used data suitable for training the model.
The assessment determined that the F1-score was the most important for analyzing the model's effectiveness (Naidu et al., 2023). And not only it proved how accurately the model is at predicting the sentiment but also gave weight to the aspect of precision and recall. This helped the model to achieve good performance in the classification between positive and negative reviews without favoring any of the two.
When it comes to applications of the model, it has been effective in issues related to sentiment analysis. The target audience may include using the model in order to examine customers' feedbacks, social media comments, and online reviews. Possibilities for improvement in providing for customer needs, enhancing the marketing strategy, and further developing the product can be obtained from such an analysis. The model can also help in real-time decision-making as it will give real-time reaction from the public about the products or services.
However, they performs very poorly for other sentences or different domain or for the data set containing different kind of language such as sarcastic language etc. This limitation can be prevented in future work by refining the model and further training the model (Sun et al., 2022).
Future Work and Recommendations
Future work can consider the application of transfer learning and ensemble methods in order to enhance the performance of the developed sentiment analysis model. It is possible to improve the accuracy and consider more complicated language patterns by either using pre-trained models on different sets of data or mix several models. As well, increasing dataset size or utilizing domain-specific corpora may also be used to further enhance the performance and generalization of the model for different tasks.
The second is to extend the model to multilingual analysis. Today, the given model works with only the English language movie reviews (Agüero-Torales, Abreu Salas and López-Herrera, 2021b). It would be useful if the model can support multiple languages like Spanish, French or Chinese in order to expand its market. For this, there are certain multilingual transformers such as mBERT or XLM-R. These models are built in a way to support a broad range of languages and help the sentiment analysis model to work regardless of the language used.
Another promising direction is in-line approaches or in real-time applications are the second promising approach. The model could be used in real time social media monitoring for business organization whereby they monitor the customers feeling in real time. Implementation of the model in customer service chatbots can give real-time sentiment analysis during the customer interaction, which would then improve customer experience.
Third, there are challenges related to dealing with computational issues during the model fine-tuning stage (Ding et al., 2023). However, it is possible to use some solutions such as model quantization, data augmentation, and the use of cloud services that have a better computational capacity. Doing so can enhance the given model further and allow it to be extended to such real-life domains as healthcare or education to analyze patients' opinions or students' attitudes.
References
- Abdullah Al Maruf, Khanam, F., Md. MahmudulHaque, ZakariaMasudJiyad, FirojMridha and Aung, Z. (2024). Challenges and Opportunities of Text-based Emotion Detection: a Survey. IEEE access, pp.1-1. doi:https://doi.org/10.1109/access.2024.3356357.
- Aftab, M., Ahmad, T., Adeel, S., Bhatti, S.H. and Irfan, M. (2025). Hyper-parameter Tuning through Innovative Designing to Avoid over-fitting in Machine Learning modelling: a Case Study of Small Data Sets. Journal of Statistical Computation and Simulation, pp.1-15. doi:https://doi.org/10.1080/00949655.2025.2465787.
- Aghaei, R., Kiaei, A.A., Boush, M., Vahidi, J., Zavvar, M., Barzegar, Z. and Rofoosheh, M. (2025). Harnessing the Potential of Large Language Models in Modern Marketing Management: Applications, Future Directions, and Strategic Recommendations. [online] arXiv.org. Available at: https://arxiv.org/abs/2501.10685.
- Agüero-Torales, M.M., Abreu Salas, J.I. and López-Herrera, A.G. (2021). Deep Learning and Multilingual Sentiment Analysis on Social Media data: an Overview. Applied Soft Computing, 107, p.107373. doi:https://doi.org/10.1016/j.asoc.2021.107373.
- Alaparthi, S. and Mishra, M. (2021). BERT: a Sentiment Analysis Odyssey. Journal of Marketing Analytics, 9(2), pp.118-126. doi:https://doi.org/10.1057/s41270-021-00109-8.
- Alasmari, A., Farooqi, N. and Alotaibi, Y. (2024). Sentiment Analysis of Pilgrims Using CNN-LSTM Deep Learning Approach. PeerJ Computer Science, 10, p.e2584. doi:https://doi.org/10.7717/peerj-cs.2584.
- Alejandra, B., Helena, F., Cantu-Ortiz, F.J. and Ceballos, H.G. (2023). Sentiment Analysis of IMDB Movie Reviews Using Deep Learning Techniques. Lecture notes in networks and systems, pp.421-434. doi:https://doi.org/10.1007/978-981-99-3236-8_33.
- Alexandros Zeakis, Papadakis, G., Dimitrios Skoutas and Manolis Koubarakis (2023). Pre-Trained Embeddings for Entity Resolution: an Experimental Analysis. Proceedings of the VLDB Endowment, 16(9), pp.2225-2238. doi:https://doi.org/10.14778/3598581.3598594.
- Ali, Farooq, Q., Imran, A. and Hindi, K.E. (2025). A Systematic Literature Review on Sentiment Analysis techniques, challenges, and Future Trends. Knowledge and Information Systems. doi:https://doi.org/10.1007/s10115-025-02365-x.
- Arias-Duart, A., Mariotti, E., Garcia-Gasulla, D. and Alonso-Moral, J.M. (2023). A Confusion Matrix for Evaluating Feature Attribution Methods. Thecvf.com, pp.3709-3714.
- Bibi, M., Abbasi, W.A., Aziz, W., Khalil, S., Uddin, M., Iwendi, C. and Gadekallu, T.R. (2022). A Novel Unsupervised Ensemble Framework Using concept-based Linguistic Methods and Machine Learning for Twitter Sentiment Analysis. Pattern Recognition Letters, 158, pp.80-86. doi:https://doi.org/10.1016/j.patrec.2022.04.004.
- Birjali, M., Kasri, M. and Beni-Hssane, A. (2021). A Comprehensive Survey on Sentiment analysis: Approaches, Challenges and Trends. Knowledge-Based Systems, 226(1), p.107134. doi:https://doi.org/10.1016/j.knosys.2021.107134.
- Capone, L., Auriemma, S., Miliani, M., Alessandro Bondielli and Lenci, A. (2024). Lost in Disambiguation: How Instruction-Tuned LLMs Master Lexical Ambiguity. ACL Anthology, pp.148-156.
- Chia, Z.L., Ptaszynski, M., Masui, F., Leliwa, G. and Wroczynski, M. (2021). Machine Learning and Feature engineering-based Study into Sarcasm and Irony Classification with Application to Cyberbullying Detection. Information Processing & Management, 58(4), p.102600. doi:https://doi.org/10.1016/j.ipm.2021.102600.
- Chirgaiya, S., Sukheja, D., Shrivastava, N. and Rawat, R. (2021). Analysis of Sentiment Based Movie Reviews Using Machine Learning Techniques. Journal of Intelligent & Fuzzy Systems, pp.1-8. doi:https://doi.org/10.3233/jifs-189866.
- Ding, N., Qin, Y., Yang, G., Wei, F., Yang, Z., Su, Y., Hu, S., Chen, Y., Chan, C.-M., Chen, W., Yi, J., Zhao, W., Wang, X., Liu, Z., Zheng, H.-T., Chen, J., Liu, Y., Tang, J., Li, J. and Sun, M. (2023). Parameter-efficient fine-tuning of large-scale pre-trained Language Models. Nature Machine Intelligence. doi:https://doi.org/10.1038/s42256-023-00626-4.
- Domadula, P.S.S.V. and Sayyaparaju, S.S. (2023). Sentiment Analysis of IMDB Movie Reviews : a Comparative Study of Lexicon Based Approach and BERT Neural Network Model. [online] www.diva-portal.org. Available at: https://www.diva-portal.org/smash/record.jsf?pid=diva2:1779708.
- Foody, G.M. (2023). Challenges in the Real World Use of Classification Accuracy metrics: from Recall and Precision to the Matthews Correlation Coefficient. PLOS ONE, 18(10), pp.e0291908-e0291908. doi:https://doi.org/10.1371/journal.pone.0291908.
- Frenda, S., Cignarella, A.T., Basile, V., Bosco, C., Patti, V. and Rosso, P. (2022). The Unbearable Hurtfulness of Sarcasm. Expert Systems with Applications, 193, p.116398. doi:https://doi.org/10.1016/j.eswa.2021.116398.
- Ghosh, A. (2022). Sentiment Analysis of IMDb Movie Reviews : a Comparative Study on Performance of Hyperparameter-tuned Classification Algorithms. [online] IEEE Xplore. doi:https://doi.org/10.1109/ICACCS54159.2022.9784961.
- Guo, J. (2022). Deep Learning Approach to Text Analysis for Human Emotion Detection from Big Data. Journal of Intelligent Systems, 31(1), pp.113-126. doi:https://doi.org/10.1515/jisys-2022-0001.
- Gupta, S., Ranjan, R. and Singh, S.N. (2024). Comprehensive Study on Sentiment Analysis: from Rule-based to Modern LLM Based System. [online] arXiv.org. Available at: https://arxiv.org/abs/2409.09989.
- Hutson, J. and Ratican, J. (2024). Advancing Sentiment Analysis through Emotionally-Agnostic Text Mining in Large Language Models (LLMS). Journal of Biosensors and Bioelectronics Research, pp.1-8. doi:https://doi.org/10.47363/jbber/2024(2)118.
- Kaur, G. and Sharma, A. (2023). A deep learning-based model using hybrid feature extraction approach for consumer sentiment analysis. Journal of Big Data, 10(1). doi:https://doi.org/10.1186/s40537-022-00680-6.
- Koroteev, M.V. (2021). BERT: a Review of Applications in Natural Language Processing and Understanding. arXiv:2103.11943 [cs].
- Laurer, M., Wouter van Atteveldt, Casas, A. and Kasper Welbers (2023). Less Annotating, More Classifying: Addressing the Data Scarcity Issue of Supervised Machine Learning with Deep Transfer Learning and BERT-NLI. pp.1-33. doi:https://doi.org/10.1017/pan.2023.20.
- Lepistö, K., Saunila, M. and Ukko, J. (2022). Enhancing Customer satisfaction, Personnel Satisfaction and Company Reputation with Total Quality management: Combining Traditional and New Views. Benchmarking: An International Journal, 31(1), pp.75-97. doi:https://doi.org/10.1108/bij-12-2021-0749.
- Mughal, N., Mujtaba, G., Kumar, A. and Sher Muhammad Daudpota (2024). Comparative Analysis of Deep Natural Networks and Large Language Models for Aspect-Based Sentiment Analysis. IEEE access, pp.1-1. doi:https://doi.org/10.1109/access.2024.3386969.
- Naidu, G., Tranos Zuva and Elias Mmbongeni Sibanda (2023). A Review of Evaluation Metrics in Machine Learning Algorithms. Lecture notes in networks and systems, 724, pp.15-25. doi:https://doi.org/10.1007/978-3-031-35314-7_2.
- NeerajAnand Sharma, Ali and Muhammad AshadKabir (2024). A Review of Sentiment analysis: tasks, applications, and Deep Learning Techniques. International journal of data science and analytics. doi:https://doi.org/10.1007/s41060-024-00594-x.
- Nunes, H., Figueiredo, E., Rocha, L., Nadi, S., Ferreira, F. and Esteves, G. (2025). Evaluating the Effectiveness of LLMs in Fixing Maintainability Issues in Real-World Projects. [online] arXiv.org. Available at: https://arxiv.org/abs/2502.02368 [Accessed 8 Mar. 2025].
- Obiedat, R., Qaddoura, R., Al-Zoubi, A.M., Al-Qaisi, L., Harfoushi, O., Alrefai, M. and Faris, H. (2022). Sentiment Analysis of Customers' Reviews Using a Hybrid Evolutionary SVM-Based Approach in an Imbalanced Data Distribution. IEEE Access, 10, pp.22260-22273. doi:https://doi.org/10.1109/access.2022.3149482.
- Oliveira, E. e, Rodrigues, M., João Paulo Pereira, Lopes, A.M., Ivana Ilic Mestric and Sandro Bjelogrlic (2024). Unlabeled learning algorithms and operations: overview and future trends in defense sector. Artificial Intelligence Review, 57(3). doi:https://doi.org/10.1007/s10462-023-10692-0.
- Onan, A. and Tocoglu, M.A. (2021). A Term Weighted Neural Language Model and Stacked Bidirectional LSTM Based Framework for Sarcasm Identification. IEEE Access, 9, pp.7701-7722. doi:https://doi.org/10.1109/access.2021.3049734.
- Osaba, E., Villar-Rodriguez, E., Del Ser, J., Nebro, A.J., Molina, D., LaTorre, A., Suganthan, P.N., Coello Coello, C.A. and Herrera, F. (2021). A Tutorial on the design, Experimentation and Application of Metaheuristic Algorithms to real-World Optimization Problems. Swarm and Evolutionary Computation, 64, p.100888. doi:https://doi.org/10.1016/j.swevo.2021.100888.
- Qasim, R., Bangyal, W.H., Alqarni, M.A. and Ali Almazroi, A. (2022). A Fine-Tuned BERT-Based Transfer Learning Approach for Text Classification. Journal of Healthcare Engineering, 2022, p.3498123. doi:https://doi.org/10.1155/2022/3498123.
- Rahman, S.A., Tuckerman, L., Vorley, T. and Gherhes, C. (2021). Resilient Research in the Field: Insights and Lessons from Adapting Qualitative Research Projects during the COVID-19 Pandemic. International Journal of Qualitative Methods, 20(1), p.160940692110161. doi:https://doi.org/10.1177/16094069211016106.
- Sivakumar, S. and Rajalakshmi, R. (2022). Context-aware Sentiment Analysis with attention-enhanced Features from Bidirectional Transformers. Social Network Analysis and Mining, 12(1). doi:https://doi.org/10.1007/s13278-022-00910-y.
- Soydaner, D. (2022). Attention Mechanism in Neural networks: Where It Comes and Where It Goes. Neural Computing and Applications, 34(16), pp.13371-13385. doi:https://doi.org/10.1007/s00521-022-07366-3.
- Sun, T., Lu, C., Zhang, T. and Ling, H. (2022). Safe Self-Refinement for Transformer-Based Domain Adaptation. Thecvf.com, pp.7191-7200.
- Tao, C., Shen, T., Gao, S., Zhang, J., Li, Z., Tao, Z. and Ma, S. (2024). LLMs Are Also Effective Embedding Models: an In-depth Overview. [online] arXiv.org. Available at: https://arxiv.org/abs/2412.12591 [Accessed 8 Mar. 2025].
- Ullah, S., MdMohsinKabir, Talha Bin Sarwar, Safran, M., Sultan Alfarhood and Mridha, M.F. (2024). A Multimodal Approach to cross-lingual Sentiment Analysis with Ensemble of Transformer and LLM. Scientific reports, 14(1). doi:https://doi.org/10.1038/s41598-024-60210-7.
- Verma, S. (2022). Sentiment Analysis of Public Services for Smart society: Literature Review and Future Research Directions. Government Information Quarterly, 39(3), p.101708. doi:https://doi.org/10.1016/j.giq.2022.101708.
- Wankhade, M., Rao, A.C.S. and Kulkarni, C. (2022). A Survey on Sentiment Analysis methods, applications, and Challenges. Artificial Intelligence Review, 55(55).
- Yang, H., Zhao, Y., Wu, Y., Wang, S., Zheng, T., Zhang, H., Ma, Z., Che, W. and Qin, B. (2024). Large Language Models Meet Text-Centric Multimodal Sentiment Analysis: a Survey. [online] arXiv.org. Available at: https://arxiv.org/abs/2406.08068.
- Yates, L.A., Aandahl, Z., Richards, S.A. and Brook, B.W. (2022). Cross Validation for Model selection: a Review with Examples from Ecology. Ecological Monographs, 93(1). doi:https://doi.org/10.1002/ecm.1557.
- Zhang, R., Cheng, Y., Wang, L., Sang, N. and Xu, J. (2023). Efficient Bank Fraud Detection with Machine Learning. Journal of Computational Methods in Engineering Applications, pp.1-10. doi:https://doi.org/10.62836/jcmea.v3i1.030102.
- Zhang, W., Deng, Y., Liu, B., Pan, S.J. and Bing, L. (2023). Sentiment Analysis in the Era of Large Language Models: a Reality Check. [online] arXiv.org. doi:https://doi.org/10.48550/arXiv.2305.15005.
- Zheng, H., Xu, K., Zhou, H., Wang, Y. and Su, G. (2024). Medication Recommendation System Based on Natural Language Processing for Patient Emotion Analysis. Academic Journal of Science and Technology, 10(1), pp.62-68. doi:https://doi.org/10.54097/v160aa61.
- Online
- Quantib. (n.d.). How Does Deep Learning Work in Radiology?. [online] Available at: https://www.quantib.com/blog/how-does-deep-learning-work-in-radiology
- ResearchGate. (n.d.). An overview of Bidirectional Encoder Representations from Transformers (BERT). [online] Available at: https://www.researchgate.net/figure/An-overview-of-Bidirectional-Encoder-Representations-from-Transformers-BERT-left-and_fig2_350819820
- SlideShare. (n.d.). Traditional Model Limitations. [online] Available at: https://www.slideshare.net/slideshow/traditional-model-limitations/9727940
- Towards AI. (n.d.). Transformer Architecture Part 1. [online] Available at: https://pub.towardsai.net/transformer-architecture-part-1-d157b54315e6

UPTO55%
Avail The Benefit Today!
To View this & another 50000+ free